1.What is spark? Apache Spark is open source, wide range data processing engine. It is data processing engine with high APIs. It allows data worker to execute streaming, machine learning or SQL workloads. These jobs need fast iterative access to datasets. 2. what is sparkcontext? The most important step of any Spark driver application is to generate SparkContext. It allows your Spark Application to access Spark Cluster with the help of Resource Manager. The resource manager can be one of these three- Spark Standalone, YARN, Apache Mesos. 3. How to Create SparkContext Class? If you want to create SparkContext, first SparkConf should be made. The SparkConf has a configuration parameter that our Spark driver application will pass to SparkContext. Some of these parameter defines properties of Spark driver application. While some are used by Spark to allocate resources on the cluster, like the number, memory size, and cores used by executor running on the worker nodes. In short, it guides how to access the Spark cluster. After the creation of a SparkContext object, we can invoke functions such as textFile, sequenceFile, parallelize etc. The different contexts in which it can run are local, yarn-client, Mesos URL and Spark URL. Once the SparkContext is created, it can be used to create RDDs, broadcast variable, and accumulator, ingress Spark service and run jobs. All these things can be carried out until SparkContext is stopped. 4. what is a stage? A stage is nothing but a step in a physical execution plan. It is basically a physical unit of the execution plan. It is a set of parallel tasks i.e. one task per partition. In other words, each job which gets divided into smaller sets of tasks is a stage. Although, it totally depends on each other. However, we can say it is as same as the map and reduce stages in MapReduce. Stages in Apache spark have two categories 1. ShuffleMapStage in Spark 2. ResultStage in Spark 5.What is spark core? Spark Core is a common execution engine for Spark platform. It provides parallel and distributed processing for large data sets. All the components on the top of it. Spark core provides speed through in-memory computation. And for ease of development, it also supports Java, Scala and Python APIs. RDD is the basic data structure of Spark Core. RDDs are immutable, a partitioned collection of record that can operate in parallel. 6.What is an RDD? RDD (Resilient Distributed Dataset) is the fundamental data structure of Apache Spark which are an immutable collection of objects which computes on the different node of the cluster. Each and every dataset in Spark RDD is logically partitioned across many servers so that they can be computed on different nodes of the cluster. Resilient, i.e. fault-tolerant with the help of RDD lineage graph(DAG) and so able to recompute missing or damaged partitions due to node failures. Distributed, since Data resides on multiple nodes. Dataset represents records of the data you work with. The user can load the data set externally which can be either JSON file, CSV file, text file or database via JDBC with no specific data structure.Hence, each and every dataset in RDD is logically partitioned across many servers so that they can be computed on different nodes of the cluster. RDDs are fault tolerant i.e. It posses self-recovery in the case of failure. There are three ways to create RDDs in Spark such as – Data in stable storage, other RDDs, and parallelizing already existing collection in driver program. One can also operate Spark RDDs in parallel with a low-level API that offers transformations and actions. Spark RDD can also be cached and manually partitioned. Caching is beneficial when we use RDD several times. And manual partitioning is important to correctly balance partitions. Generally, smaller partitions allow distributing RDD data more equally, among more executors. Hence, fewer partitions make the work easy. Programmers can also call a persist method to indicate which RDDs they want to reuse in future operations. Spark keeps persistent RDDs in memory by default, but it can spill them to disk if there is not enough RAM. Users can also request other persistence strategies, such as storing the RDD only on disk or replicating it across machines, through flags to persist. 7. What is Transformation ? Spark RDD Transformations are functions that take an RDD as the input and produce one or many RDDs as the output. They do not change the input RDD (since RDDs are immutable and hence one cannot change it), but always produce one or more new RDDs by applying the computations they represent e.g. Map(), filter(), reduceByKey() etc. Transformations are lazy operations on an RDD in Apache Spark. It creates one or many new RDDs, which executes when an Action occurs. Hence, Transformation creates a new dataset from an existing one.Certain transformations can be pipelined which is an optimization method, that Spark uses to improve the performance of computations. There are two kinds of transformations: narrow transformation, wide transformation. Narrow transformations are the result of map, filter and in which data to transform id from a single partition only, i.e. it is self-sustained. An output RDD has partitions with records that originate from a single partition in the parent RDD. Wide Transformations Wide transformations are the result of groupByKey and reduceByKey. The data required to compute the records in a single partition may reside in many partitions of the parent RDD. Wide transformations are also called shuffle transformations as they may or may not depend on a shuffle. All of the tuples with the same key must end up in the same partition, processed by the same task. To satisfy these operations, Spark must execute RDD shuffle, which transfers data across the cluster and results in a new stage with a new set of partitions. 8. Actions in spark? An Action in Spark returns final result of RDD computations. It triggers execution using lineage graph to load the data into original RDD, carry out all intermediate transformations and return final results to Driver program or write it out to file system. Lineage graph is dependency graph of all parallel RDDs of RDD. Actions are RDD operations that produce non-RDD values. They materialize a value in a Spark program. An Action is one of the ways to send result from executors to the driver. First(), take(), reduce(), collect(), the count() is some of the Actions in spark. Using transformations, one can create RDD from the existing one. But when we want to work with the actual dataset, at that point we use Action. When the Action occurs it does not create the new RDD, unlike transformation. Thus, actions are RDD operations that give no RDD values. Action stores its value either to drivers or to the external storage system. It brings laziness of RDD into motion. 9. what are the components of spark ? Spark Core: Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines RDDs, Spark SQL: Spark SQL is Spark’s package for working with structured data. It allows querying data via SQL as well as the HQL. Spark Streaming: Spark Streaming is a Spark component that enables processing of live streams of data. Examples of data streams include logfiles generated by production web servers. MLlib: Spark comes with a library containing common machine learning (ML) functionality, called MLlib. MLlib provides multiple types of machine learning algorithms. GraphX: GraphX is a library for manipulating graphs (e.g., a social network’s friend graph) and performing graph-parallel computations. 10.Explain components of spark Execution? Using spark-submit, the user submits an application. In spark-submit, we invoke the main() method that the user specifies. It also launches the driver program. The driver program asks for the resources to the cluster manager that we need to launch executors. The cluster manager launches executors on behalf of the driver program. The driver process runs with the help of user application. Based on the actions and transformation on RDDs, the driver sends work to executors in the form of tasks. The executors process the task and the result sends back to the driver through the cluster manager. 11.what is PairRDD? Spark provides special operations on RDDs containing key/value pairs. These RDDs are called pair RDDs. Pair RDDs are a useful building block in many programs, as they expose operations that allow you to act on each key in parallel.For example, pair RDDs have a reduceByKey() method that can aggregate data separately for each key, and a join() method that can merge two RDDs together by grouping elements with the same key. 12. Explain Map and flatMap functions? A map is a transformation operation in Apache Spark. It applies to each element of RDD and it returns the result as new RDD. In the Map, operation developer can define his own custom business logic. The same logic will be applied to all the elements of RDD. Spark Map function takes one element as input process it according to custom code (specified by the developer) and returns one element at a time. Map transforms an RDD of length N into another RDD of length N. The input and output RDDs will typically have the same number of records. A flatMap is a transformation operation. It applies to each element of RDD and it returns the result as new RDD. It is similar to Map, but FlatMap allows returning 0, 1 or more elements from map function. In the FlatMap operation, a developer can define his own custom business logic. The same logic will be applied to all the elements of the RDD. A FlatMap function takes one element as input process it according to custom code (specified by the developer) and returns 0 or more element at a time. flatMap() transforms an RDD of length N into another RDD of length M. a. FlatMap Transformation Scala Example val result = data.flatMap (line => line.split(" ") ) Above flatMap transformation will convert a line into words. One word will be an individual element of the newly created RDD. 13.What are single RDD and Multi RDD transformations? Single RDD transformation is a transformation that applies on each element on single RDD and returns the result as single RDD. examples:map(),flatMap(),SortBy(),Distinct Multi RDD transformations are transformations that applies on 2 or more RDDs and returns result as single RDD. examples: Union, subtract, Intersection,Zip 14.how you create a RDD and show with example?
There are following ways to create RDD in Spark are:
1.Using parallelized collection.
2.From external datasets (Referencing a dataset in external storage system ).
15.Explain how RDDs are distributed across cluster? 16.How spark executes RDD operations in Parallel?
Parallel Processing of RDD
Let me ask you a simple question. Given the above RDD, If I want to count the number of lines in that RDD, Can we do it in parallel? No brainer. Right?
We already have five partitions. I will give one partition to each executor and ask them to count the lines in the given partition. Then I will take the counts back from these executors and sum it. Simple. Isn't it? That's what the Spark does.
Calculating count is a simple thing. However, the mechanism of parallelism in Spark is the same. There are two main variables to control the degree of parallelism in Apache Spark.
The number of partitions
The number of executors
If you have ten partitions, you can achieve ten parallel processes at the most. However, if you have just two executors, all those ten partitions will be queued to those two executors.
Let's do something little simple and take our understanding to the next level. Here is an example in Scala.
val flistRDD = sc.textFile("/home/prashant/flist.txt",5)val arrayRDD = flistRDD.map(x=> x.split("/"))val kvRDD = arrayRDD.map(a =>(a(1),1))val fcountRDD= kvRDD.reduceByKey((x,y)=> x+y)
fcountRDD.collect()/* Sample entries from the data file
/etc/abrt
/etc/abrt/plugins
/etc/abrt/plugins/CCpp.conf
/etc/reader.conf
/etc/fonts
/etc/fonts/fonts.conf
/etc/fonts/fonts.dtd
/etc/fonts/conf.d
*/
The above example loads a data file. The file contains the list of directories and files in my local system. I have listed some sample entries above.
Line one loads a text file into an RDD. The file is quite small. If you keep it in HDFS, it may have one or two blocks in HDFS, So it is likely that you get one or two partitions by default. However, we want to make five partitions of this data file and hence we set the second argument of the textFile API to 5.
The line two executes a map method on the first RDD and returns a new RDD. We already know that RDDs are immutable. So, we can't modify the first RDD. Instead, we take the first RDD, perform a map operation and create a new RDD. The map operation splits each line into an array of words. Hence, the new RDD is a collection of Arrays.
The third line executes another map method over the arrayRDD. This time, we generate a tuple (key-value pair). I am taking the first element of the array as my key. The value is a hardcoded numeric one. What am I trying to do? I am trying to count the number of entries for each unique directory listing in the file. That's why I am taking the directory name as a key and one as a value. Once I have kvRDD, I can easily count the number of files. All I have to do is to group all the values by the key and sum up the 1s. That's what the fourth line is doing (ReduceByKey). The ReduceByKey means, group by key and sum the values. Finally, I collect all the data back from the executors to the driver. 17.how you control parallelization through partitioning?
RDD operations are executed in parallel on each partition. Tasks are executed on the Worker Nodes where the data is stored.
Some operations preserve partitioning, such as map, flatMap, filter, distinct, and so on. Some operations repartition, such as reduceByKey, sortByKey, join, groupByKey, and so on.
18.how to view and monitor tasks and stages? 19.Why some stages will take time while executing and what will be the reason for it? 20.what is Stage,Task,application in spark? A task is a unit of work that sends to the executor. Each stage has some task, one task per partition. The Same task is done over different partitions of RDD. The job is parallel computation consisting of multiple tasks that get spawned in response to actions in Apache Spark. Each job divides into smaller sets of tasks called stages that depend on each other. Stages are classified as computational boundaries. All computation cannot be done in a single stage. It achieves over many stages. 21.create an RDD from textfile that has 4 partitions? 22.Explain how RDD lineage is created?
RDD Lineage (aka RDD operator graph or RDD dependency graph) is a graph of all the parent RDDs of a RDD. It is built as a result of applying transformations to the RDD and creates a logical execution plan.
Note
The execution DAG or physical execution plan is the DAG of stages.
Note
The following diagram uses cartesian or zip for learning purposes only. You may use other operators to build a RDD graph.
Figure 1. RDD lineage val r00 = sc.parallelize(0 to 9) val r01 = sc.parallelize(0 to 90 by 10) val r10 = r00 cartesian r01 val r11 = r00.map(n => (n, n)) val r12 = r00 zip r01 val r13 = r01.keyBy(_ / 20) val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)
Logical Execution Plan
Getting RDD Lineage Graph — toDebugString Method toDebugString: String scala> val wordCount = sc.textFile("README.md").flatMap(_.split("\\s+")).map((_, 1)).reduceByKey(_ + _) wordCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[21] at reduceByKey at <console>:24scala> wordCount.toDebugString res13: String = (2) ShuffledRDD[21] at reduceByKey at <console>:24 [] +-(2) MapPartitionsRDD[20] at map at <console>:24 [] | MapPartitionsRDD[19] at flatMap at <console>:24 [] | README.md MapPartitionsRDD[18] at textFile at <console>:24 [] | README.md HadoopRDD[17] at textFile at <console>:24 [] scala> wordCount.getNumPartitions res14: Int = 2 $ ./bin/spark-shell --conf spark.logLineage=truescala> sc.textFile("README.md", 4).count ... 15/10/17 14:46:42 INFO SparkContext: Starting job: count at <console>:25 15/10/17 14:46:42 INFO SparkContext: RDD's recursive dependencies: (4) MapPartitionsRDD[1] at textFile at <console>:25 [] | README.md HadoopRDD[0] at textFile at <console>:25 []
The above RDD graph could be the result of the following series of transformations:
A RDD lineage graph is hence a graph of what transformations need to be executed after an action has been called.
You can learn about a RDD lineage graph using RDD.toDebugString method.
Logical Execution Plan starts with the earliest RDDs (those with no dependencies on other RDDs or reference cached data) and ends with the RDD that produces the result of the action that has been called to execute.
toDebugString uses indentations to indicate a shuffle boundary.
The numbers in round brackets show the level of parallelism at each stage, e.g. (2) in the above output.
With spark.logLineage property enabled, toDebugString is included when executing an action.
23.Explain about RDD persistance and how it will be useful?
Programmers can also call a persist method to indicate which RDDs they want to reuse in future operations. Spark keeps persistent RDDs in memory by default, but it can spill them to disk if there is not enough RAM. Users can also request other persistence strategies, such as storing the RDD only on disk or replicating it across machines, through flags to persist. Spark RDD persistence is an optimization technique in which saves the result of RDD evaluation. Using this we save the intermediate result so that we can use it further if required. It reduces the computation overhead. We can make persisted RDD through cache() and persist() methods. When we use the cache() method we can store all the RDD in-memory. We can persist the RDD in memory and use it efficiently across parallel operations. The difference between cache() and persist() is that using cache() the default storage level is MEMORY_ONLY while using persist() we can use various storage levels 24.Describe storage levels in RDD persistance?
Using persist() we can use various storage levels to Store Persisted RDDs in Apache Spark. Let’s discuss each RDD storage level one by one-
a. MEMORY_ONLY
In this storage level, RDD is stored as deserialized Java object in the JVM. If the size of RDD is greater than memory, It will not cache some partition and recompute them next time whenever needed. In this level the space used for storage is very high, the CPU computation time is low, the data is stored in-memory. It does not make use of the disk.
b. MEMORY_AND_DISK
In this level, RDD is stored as deserialized Java object in the JVM. When the size of RDD is greater than the size of memory, it stores the excess partition on the disk, and retrieve from disk whenever required. In this level the space used for storage is high, the CPU computation time is medium, it makes use of both in-memory and on disk storage.
c. MEMORY_ONLY_SER
This level of Spark store the RDD as serialized Java object (one-byte array per partition). It is more space efficient as compared to deserialized objects, especially when it uses fast serializer. But it increases the overhead on CPU. In this level the storage space is low, the CPU computation time is high and the data is stored in-memory. It does not make use of the disk.
d. MEMORY_AND_DISK_SER
It is similar to MEMORY_ONLY_SER, but it drops the partition that does not fits into memory to disk, rather than recomputing each time it is needed. In this storage level, The space used for storage is low, the CPU computation time is high, it makes use of both in-memory and on disk storage.
e. DISK_ONLY
In this storage level, RDD is stored only on disk. The space used for storage is low, the CPU computation time is high and it makes use of on disk storage.
25.Explain steps of general ML pipeline? 26.clustering, collabration and classification 27.Explain k-means? 28.Explain sqlContext? SQLContext. SQLContext is a class and is used for initializing the functionalities of Spark SQL. SparkContext class object (sc) is required for initializing SQLContextclass object. 29.what are methods of sparksql? 30.Difference between impala and sparksql? 31.Difference b/n spark streaming & batch programmitically 32.What is SchmeaRDD or Dataframe in spark? DataFrame appeared in Spark Release 1.3.0. We can term DataFrame as Dataset organized into named columns. DataFrames are similar to the table in a relational database or data frame in R /Python. It can be said as a relational table with good optimization technique. The idea behind DataFrame is it allows processing of a large amount of structured data. DataFrame contains rows with Schema. The schema is the illustration of the structure of data. DataFrame is one step ahead of RDD. Since it provides memory management and optimized execution plan. a. Custom Memory Management: This is also known as Project Tungsten. A lot of memory is saved as the data is stored in off-heap memory in binary format. Apart from this, there is no Garbage Collection overhead. Expensive Java serialization is also avoided. Since the data is stored in binary format and the schema of memory is known. b. Optimized Execution plan: This is also known as the query optimizer. Using this, an optimized execution plan is created for the execution of a query. Once the optimized plan is created final execution takes place on RDDs of Spark. 33.Spark does processing in RAM & RAM is voltaile. How data is handled with out loss in spark framework? 34.Spark architecture
Working of Spark Architecture
As you have already seen the basic architectural overview of Apache Spark, now let’s dive deeper into its working.
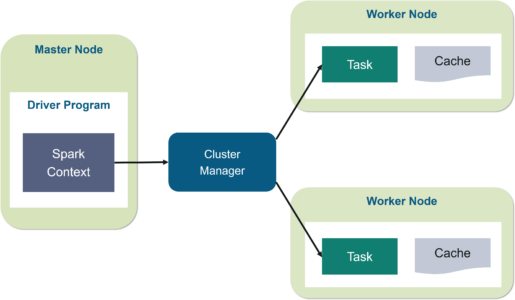
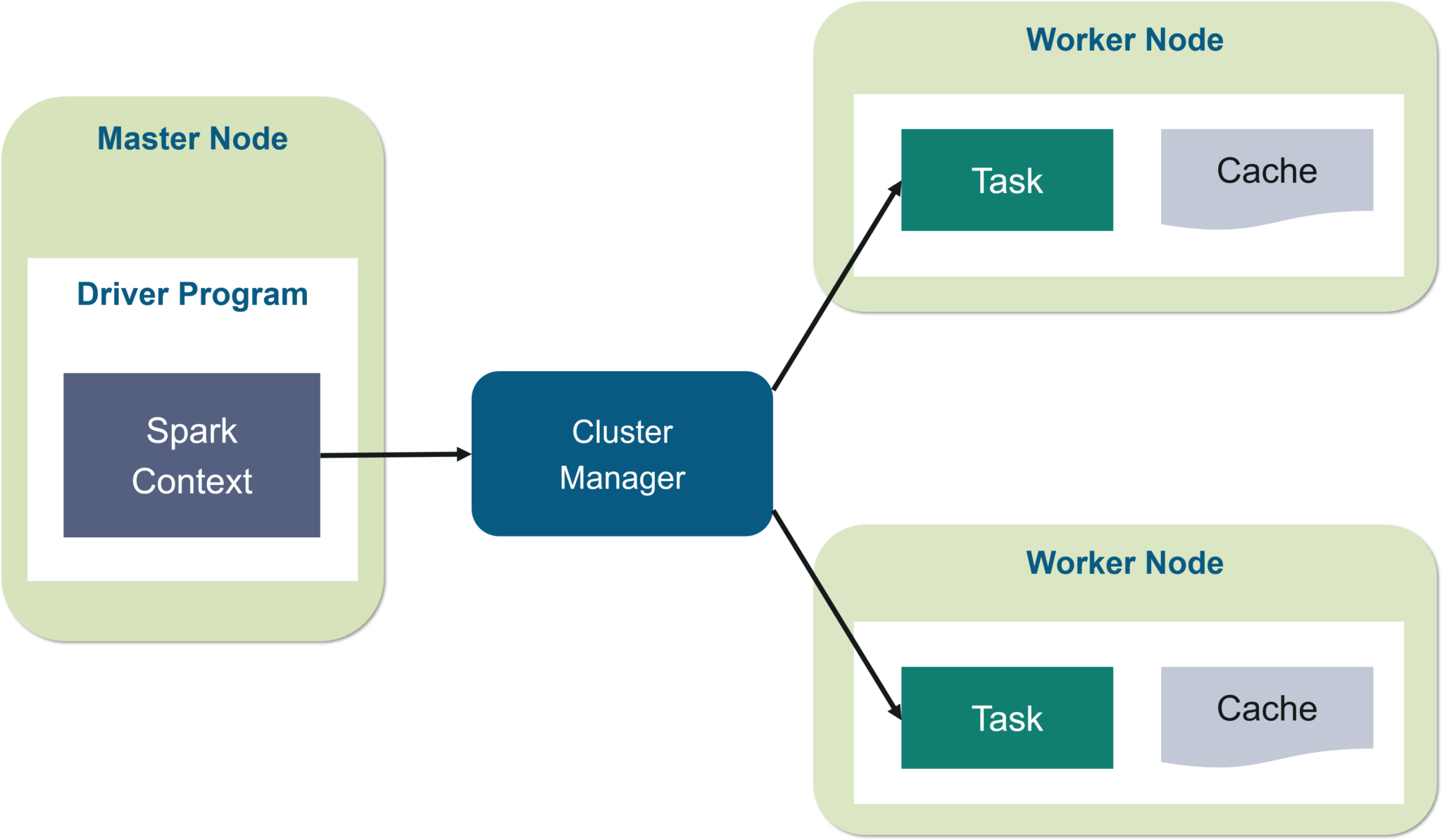
In your master node, you have the driver program, which drives your application. The code you are writing behaves as a driver program or if you are using the interactive shell, the shell acts as the driver program.
Fig: Spark Architecture
Inside the driver program, the first thing you do is, you create a Spark Context. Assume that the Spark context is a gateway to all the Spark functionalities. It is similar to your database connection. Any command you execute in your database goes through the database connection. Likewise, anything you do on Spark goes through Spark context.
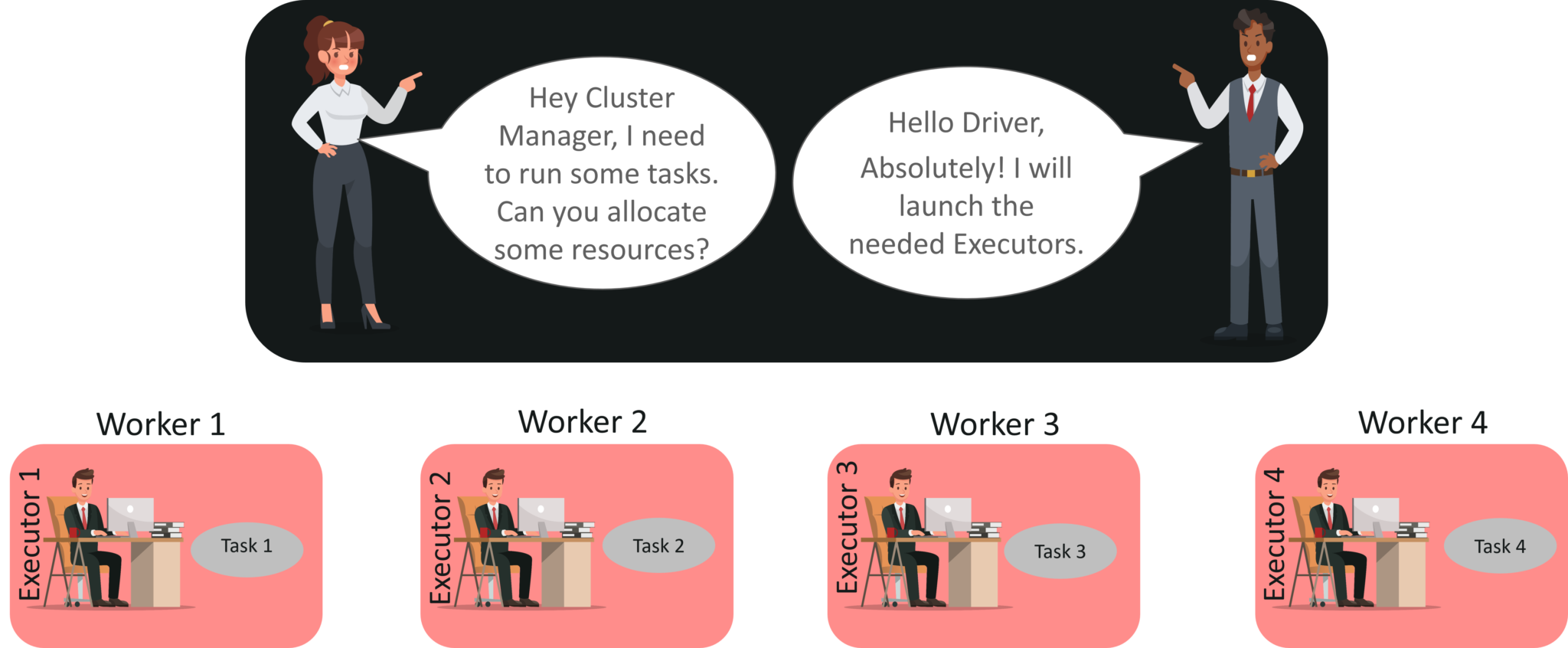
Now, this Spark context works with the cluster manager to manage various jobs. The driver program & Spark context takes care of the job execution within the cluster. A job is split into multiple tasks which are distributed over the worker node. Anytime an RDD is created in Spark context, it can be distributed across various nodes and can be cached there.
Worker nodes are the slave nodes whose job is to basically execute the tasks. These tasks are then executed on the partitioned RDDs in the worker node and hence returns back the result to the Spark Context.
Spark Context takes the job, breaks the job in tasks and distribute them to the worker nodes. These tasks work on the partitioned RDD, perform operations, collect the results and return to the main Spark Context.
If you increase the number of workers, then you can divide jobs into more partitions and execute them parallelly over multiple systems. It will be a lot faster.
With the increase in the number of workers, memory size will also increase & you can cache the jobs to execute it faster.
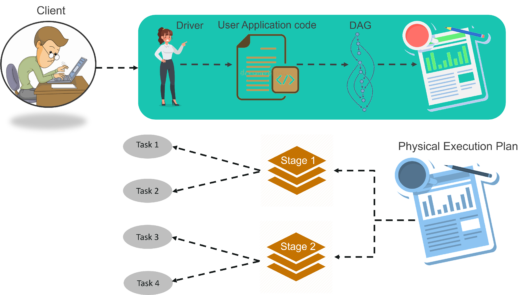
To know about the workflow of Spark Architecture, you can have a look at the infographic below:
Fig: Spark Architecture Infographic
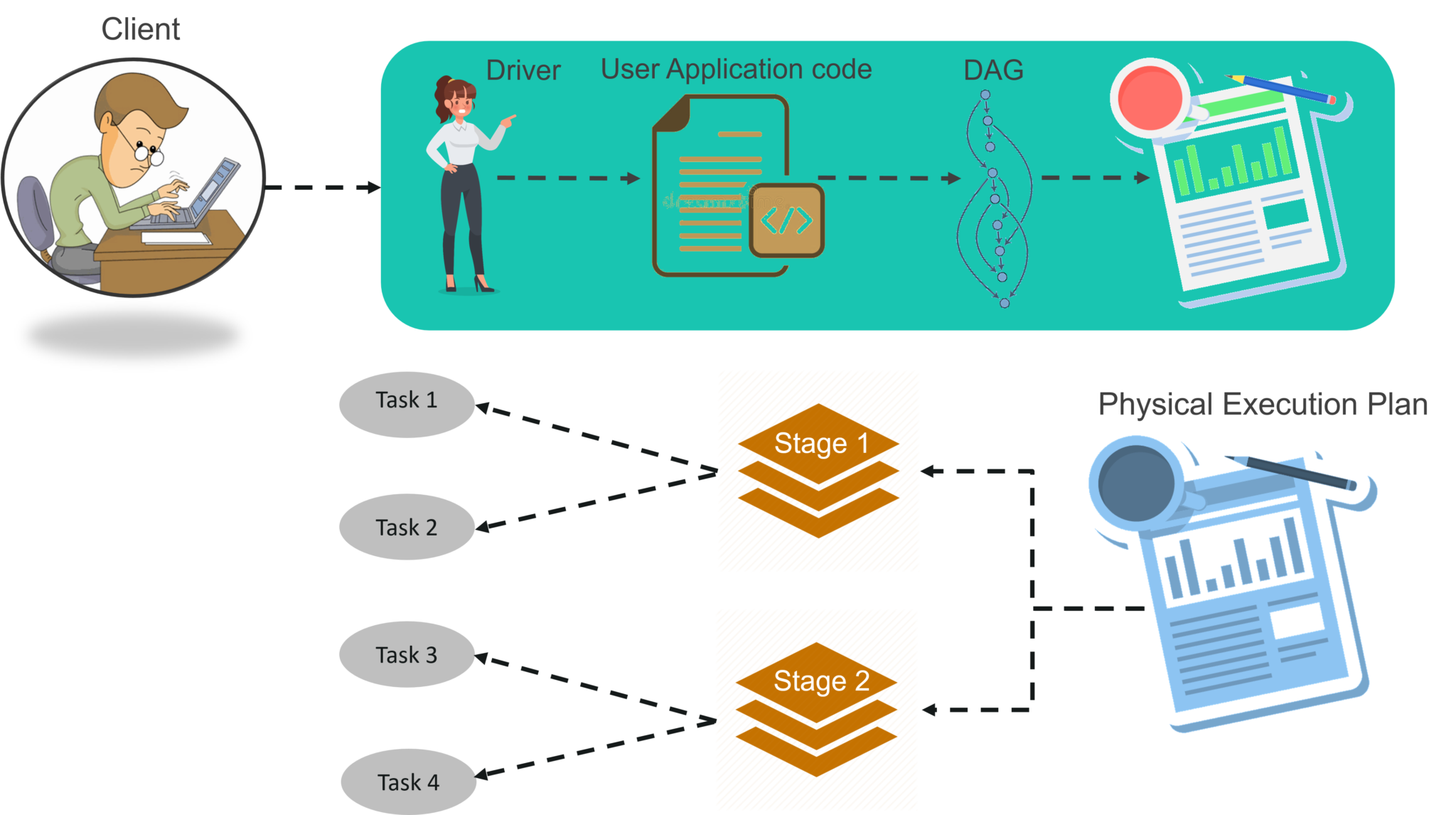
STEP 1: The client submits spark user application code. When an application code is submitted, the driver implicitly converts user code that contains transformations and actions into a logically directed acyclic graph called DAG. At this stage, it also performs optimizations such as pipelining transformations.
STEP 2: After that, it converts the logical graph called DAG into physical execution plan with many stages. After converting into a physical execution plan, it creates physical execution units called tasks under each stage. Then the tasks are bundled and sent to the cluster.
STEP 3: Now the driver talks to the cluster manager and negotiates the resources. Cluster manager launches executors in worker nodes on behalf of the driver. At this point, the driver will send the tasks to the executors based on data placement. When executors start, they register themselves with drivers. So, the driver will have a complete view of executors that are executing the task.
STEP 4: During the course of execution of tasks, driver program will monitor the set of executors that runs. Driver node also schedules future tasks based on data placement.
35.Difference b/n mapvalues and mappartitions When we use map() with a Pair RDD, we get access to both Key & value. There are times we might only be interested in accessing the value(& not key). In those case, we can use mapValues() instead of map().
In this example we use mapValues() along with reduceByKey() to calculate average for each subject
scala>val inputrdd = sc.parallelize(Seq(("maths",50),("maths",60),("english",65)))
inputrdd: org.apache.spark.rdd.RDD[(String,Int)]=ParallelCollectionRDD[29] at parallelize at :21
scala>val mapped = inputrdd.mapValues(mark =>(mark,1));
mapped: org.apache.spark.rdd.RDD[(String,(Int,Int))]=MapPartitionsRDD[30] at mapValues at :23
scala>val reduced = mapped.reduceByKey((x, y)=>(x._1 + y._1, x._2 + y._2))
reduced: org.apache.spark.rdd.RDD[(String,(Int,Int))]=ShuffledRDD[31] at reduceByKey at :25
scala>val average = reduced.map { x =>|val temp = x._2
|val total = temp._1
|val count = temp._2
|(x._1, total / count)|}
average: org.apache.spark.rdd.RDD[(String,Int)]=MapPartitionsRDD[32] at map at :27
scala>| average.collect()
res30:Array[(String,Int)]=Array((english,65),(maths,55))
Note
Operations like map() always cause the new RDD to no retain the parent partitioning information
36.Difference b/n Mappartitions & Map The method map converts each element of the source RDD into a single element of the result RDD by applying a function. mapPartitions converts each partition of the source RDD into multiple elements of the result (possibly none).
Whenever you have heavyweight initialization that should be done once for many RDD elements rather than once per RDD element, and if this initialization, such as creation of objects from a third-party library, cannot be serialized (so that Spark can transmit it across the cluster to the worker nodes), use mapPartitions() instead of map(). mapPartitions() provides for the initialization to be done once per worker task/thread/partition instead of once per RDD data element for example : see below.
val newRd = myRdd.mapPartitions(partition =>{val connection =newDbConnection/*creates a db connection per partition*/val newPartition = partition.map(record =>{
readMatchingFromDB(record, connection)}).toList // consumes the iterator, thus calls readMatchingFromDB
connection.close()// close dbconnection here
newPartition.iterator // create a new iterator})
Both map() and mapPartition() are transformations available in Rdd class. Before dive into the details, you must understand the internal of Rdd. Imagine that Rdd as a group of many Rows. Spark Api’s convert these Rows to multiple partitions.
Ex: If there are 1000 row and 10 partitions, then each partition will contain the 1000/10=100 Rows.
Now, when we apply map(func) method to rdd, the func() operation will be applied on each and every Row and in this particular case func() operation will be called 1000 times. i.e. time consuming in some time critical applications.
If we call mapPartition(func) method on rdd, the func() operation will be called on each partition instead of each row. In this particular case, it will be called 10 times(number of partition). In this way you can prevent some processing when it comes to time critical application.
37.Fault tolerance in Spark RDD – The lost data can be easily recovered in Spark RDD using lineage graph at any moment. Since for each transformation, new RDD is formed and RDDs are immutable in nature so it is easy to recover. 38.Driver variables in spark Sometimes, a variable needs to be shared across tasks, or between tasks and the driver program.Spark supports two types of shared variables: broadcast variables, which can be used to cache a value in memory on all nodes, and accumulators, which are variables that are only “added” to, such as counters and sums. 39.How do you Schedule spark streaming ? 40.Type of semantics used in Spark streaming ? 41.How can you view spark job o/p? 42.when splitting used map rather than flat map? 43.Difference b/n Dataframe & RDD?Can you run queries on dataframe? 44.To execute queries on dataframe what we need to set up? 45.Write Spark for usecase having csv file with two fields(int,char),only even numbered rows should be filtered and key should be divisible by 2 &3 46. What is catalyst optimiser? It is a functional programming construct in Scala. It is the newest and most technical component of Spark SQL. A catalyst is a query plan optimizer. It provides a general framework for transforming trees, which performs analysis/evaluation, optimization, planning, and runtime code spawning. Catalyst supports cost based optimization and rule-based optimization. It makes queries run much faster than their RDD counterparts. A catalyst is a rule-based modular library. Each rule in framework focuses on the distinct optimization 47.what are 4 spark properties? 48.what are the parameters you set while submitting the spark-job? 49.how you set driver memory,executor memory ? 50.howto schedule a sparkjob? 51.DAG properties
DAG is a finite directed graph with no directed cycles. There are finitely many vertices and edges, where each edge directed from one vertex to another. It contains a sequence of vertices such that every edge is directed from earlier to later in the sequence. In Spark, The graph here refers to navigation, and directed and acyclic refers to how it is done.
The limitations of Hadoop MapReduce became a key point to introduce DAG in Spark. The computation through MapReduce is carried in three steps:
Using a Scala interpreter, Spark interprets the code with some modifications.
Spark creates an operator graph when one writes code in Spark console.
When an Action is called on Spark RDD at a high level, Spark submits the operator graph to the DAG scheduler.
Operators are divided into stages of the task in the DAG scheduler. A stage contains task based on the partition of the input data. The DAG scheduler pipelines operators together. For example, map operators are scheduled in a single stage.
The stages are passed on to the Task Scheduler. It launches task through cluster manager. The task scheduler doesnot know the dependencies of stages.
The Workers execute the task on the slave.
52. why Dataframe? DataFrame is one step ahead of RDD. Since it provides memory management and optimized execution plan. a. Custom Memory Management: This is also known as Project Tungsten. A lot of memory is saved as the data is stored in off-heap memory in binary format. Apart from this, there is no Garbage Collection overhead. Expensive Java serialization is also avoided. Since the data is stored in binary format and the schema of memory is known. b. Optimized Execution plan: This is also known as the query optimizer. Using this, an optimized execution plan is created for the execution of a query. Once the optimized plan is created final execution takes place on RDDs of Spark. 53.what is Dataset? A Dataset is an immutable collection of objects, those are mapped to a relational schema. They are strongly-typed in nature. There is an encoder, at the core of the Dataset API. That Encoder is responsible for converting between JVM objects and tabular representation. By using Spark’s internal binary format, the tabular representation is stored that allows to carry out operations on serialized data and improves memory utilization. It also supports automatically generating encoders for a wide variety of types, including primitive types (e.g. String, Integer, Long) and Scala case classes. It offers many functional transformations (e.g. map, flatMap, filter). 54.How many partions will be their when converted from hive into Dataframe? 55.what is accumulator and broadcast variable in spark ? Accumulators, provides a simple syntax for aggregating values from worker nodes back to the driver program. One of the most common uses of accumulators is to count events that occur during job execution for debugging purposes. Spark’s second type of shared variable, broadcast variables, allows the program to efficiently send a large, read-only value to all the worker nodes for use in one or more Spark operations. They come in handy, for example, if your application needs to send a large, read-only lookup table to all the nodes.
56.how to decide the number of executors in spark submit job? Hardware – 6 Nodes and each node have 16 cores, 64 GB RAM
First on each node, 1 core and 1 GB is needed for Operating System and Hadoop Daemons, so we have 15 cores, 63 GB RAM for each node
We start with how to choose number of cores:
Number of cores = Concurrent tasks an executor can run
So we might think, more concurrent tasks for each executor will give better performance. But research shows that any application with more than 5 concurrent tasks, would lead to a bad show. So the optimal value is 5.
This number comes from the ability of an executor to run parallel tasks and not from how many cores a system has. So the number 5 stays same even if we have double (32) cores in the CPU
Number of executors:
Coming to the next step, with 5 as cores per executor, and 15 as total available cores in one node (CPU) – we come to 3 executors per node which is 15/5. We need to calculate the number of executors on each node and then get the total number for the job.
So with 6 nodes, and 3 executors per node – we get a total of 18 executors. Out of 18 we need 1 executor (java process) for Application Master in YARN. So final number is 17 executors
This 17 is the number we give to spark using –num-executors while running from spark-submit shell command
Memory for each executor:
From above step, we have 3 executors per node. And available RAM on each node is 63 GB
So memory for each executor in each node is 63/3 = 21GB.
However small overhead memory is also needed to determine the full memory request to YARN for each executor.
The formula for that overhead is max(384, .07 * spark.executor.memory)
Calculating that overhead: .07 * 21 (Here 21 is calculated as above 63/3) = 1.47
Since 1.47 GB > 384 MB, the overhead is 1.47
Take the above from each 21 above => 21 – 1.47 ~ 19 GB
57. Difference between Dataframe ,DataSet,RDD ? 58.How can we update and delete table in Spark ? 59.Difference between sparkcontext and spark session?
Spark Context:
Prior to Spark 2.0.0 sparkContext was used as a channel to access all spark functionality.
The spark driver program uses spark context to connect to the cluster through a resource manager (YARN orMesos..).
sparkConf is required to create the spark context object, which stores configuration parameter like appName (to identify your spark driver), application, number of core and memory size of executor running on worker node.
In order to use APIs of SQL, HIVE, and Streaming, separate contexts need to be created.
Example:
creating sparkConf :
val conf = new SparkConf().setAppName(“RetailDataAnalysis”).setMaster(“spark://master:7077”).set(“spark.executor.memory”, “2g”)
creation of sparkContext:
val sc = new SparkContext(conf)
Spark Session:
SPARK 2.0.0 onwards, SparkSession provides a single point of entry to interact with underlying Spark functionality and
allows programming Spark with DataFrame and Dataset APIs. All the functionality available with sparkContext are also available in sparkSession.
In order to use APIs of SQL, HIVE, and Streaming, no need to create separate contexts as sparkSession includes all the APIs.
Once the SparkSession is instantiated, we can configure Spark’s run-time config properties.
Example:
Creating Spark session:
val spark = SparkSession
.builder
.appName(“WorldBankIndex”)
.getOrCreate()
Spark 2.0.0 onwards, it is better to use sparkSession as it provides access to all the spark Functionalities that sparkContext does. Also, it provides APIs to work on DataFrames and Datasets.
60.Write spark code to read 3 csv files and place it in folder in hdfs based on timestamp.? 61.how connect to AWS using spark ? 62.Explain key features of Spark. Allows Integration with Hadoop and files included in HDFS. Spark has an interactive language shell as it has an independent Scala (the language in which Spark is written) interpreter Spark consists of RDD’s (Resilient Distributed Datasets), which can be cached across computing nodes in a cluster. Spark supports multiple analytic tools that are used for interactive query analysis , real-time analysis and graph processing. 63.What are client mode and cluster mode? Each application has a driver process which coordinates its execution. This process can run in the foreground (client mode) or in the background (cluster mode). Client mode is a little simpler, but cluster mode allows you to easily log out after starting a Spark application without terminating the application. 64.How to run spark in Standalone client mode? spark-submit \ class org.apache.spark.examples.SparkPi \ deploy-mode client \ master spark//$SPARK_MASTER_IP:$SPARK_MASTER_PORT \ $SPARK_HOME/examples/lib/spark-examples_version.jar 10 65.How to run spark in Standalone cluster mode? spark-submit \ class org.apache.spark.examples.SparkPi \ deploy-mode cluster \ master spark//$SPARK_MASTER_IP:$SPARK_MASTER_PORT \ $SPARK_HOME/examples/lib/spark-examples_version.jar 10 66. How to run spark in YARN client mode? spark-submit \ class org.apache.spark.examples.SparkPi \ deploy-mode client \ master yarn \ $SPARK_HOME/examples/lib/spark-examples_version.jar 10 67.How to run spark in YARN cluster mode? spark-submit \ class org.apache.spark.examples.SparkPi \ deploy-mode cluster \ master yarn \ $SPARK_HOME/examples/lib/spark-examples_version.jar 10 68.What is Executor memory? You can configure this using the –executor-memory argument to sparksubmit. Each application will have at most one executor on each worker, so this setting controls how much of that worker’s memory the application will claim. By default, this setting is 1 GB—you will likely want to increase it on most servers. 69.What is the maximum number of total cores? This is the total number of cores used across all executors for an application. By default, this is unlimited; that is, the application will launch executors on every available node in the cluster. For a multiuser workload, you should instead ask users to cap their usage. You can set this value through the –total-execution cores argument to spark-submit, or by configuring spark.cores.max in your Spark configuration file. 70.What does a Spark Engine do? Spark Engine is responsible for scheduling, distributing and monitoring the data application across the cluster. 71.Define Partitions? As the name suggests, partition is a smaller and logical division of data similar to ‘split’ in MapReduce. Partitioning is the process to derive logical units of data to speed up the processing process. Everything in Spark is a partitioned RDD. 72.What is RDD Lineage? Spark does not support data replication in the memory and thus, if any data is lost, it is rebuild using RDD lineage. RDD lineage is a process that reconstructs lost data partitions. The best is that RDD always remembers how to build from other datasets. 73.What is Spark Driver? Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark Master. The driver also delivers the RDD graphs to Master, where the standalone cluster manager runs. 74.What is Hive on Spark? Hive contains significant support for Apache Spark, wherein Hive execution is configured to Spark: hive> set spark.home=/location/to/sparkHome; hive> set hive.execution.engine=spark; Hive on Spark supports Spark on yarn mode by default. 75.Name commonly-used Spark Ecosystems? Spark SQL (Shark)- for developers Spark Streaming for processing live data streams GraphX for generating and computing graphs MLlib (Machine Learning Algorithms) SparkR to promote R Programming in Spark engine. 76.How Spark Streaming works? Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data streams from sources such as Kafka, Flume, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs. 77.Define Spark Streaming.Spark supports stream processing? An extension to the Spark API , allowing stream processing of live data streams. The data from different sources like Flume, HDFS is streamed and finally processed to file systems, live dashboards and databases. It is similar tobatch processing as the input data is divided into streams like batches. 78.What is GraphX? Spark uses GraphX for graph processing to build and transform interactive graphs. The GraphX component enables programmers to reason about structured data at scale. 79.What does MLlib do? MLlib is scalable machine learning library provided by Spark. It aims at making machine learning easy and scalable with common learning algorithms and use cases like clustering, regression filtering, dimensional reduction, and alike. 80.What is Spark SQL? SQL Spark, better known as Shark is a novel module introduced in Spark to work with structured data and perform structured data processing. Through this module, Spark executes relational SQL queries on the data. The core of the component supports an altogether different RDD called SchemaRDD, composed of rows objects and schema objects defining data type of each column in the row. It is similar to a table in relational database. 81.What is a Parquet file? Parquet is a columnar format file supported by many other data processing systems. Spark SQL performs both read and write operations with Parquet file and consider it be one of the best big data analytics format so far. 82.List the functions of Spark SQL? Spark SQL is capable of: Loading data from a variety of structured sources Querying data using SQL statements, both inside a Spark program and from external tools that connect to Spark SQL through standard database connectors (JDBC/ODBC). For instance, using business intelligence tools like Tableau Providing rich integration between SQL and regular Python/Java/Scala code, including the ability to join RDDs and SQL tables, expose custom functions in SQL, and more 83.Write common workflow of a Spark program? Every Spark program and shell session will work as follows: Create some input RDDs from external data. Transform them to define new RDDs using transformations like filter(). Ask Spark to persist() any intermediate RDDs that will need to be reused. Launch actions such as count() and first() to kick off a parallel computation, which is then optimized and executed by Spark. 84.What is lineage graph? As you derive new RDDs from each other using transformations, Spark keeps track of the set of dependencies between different RDDs, called the lineage graph. It uses this information to compute each RDD on demand and to recover lost data if part of a persistent RDD is lost. 85.Difference between map() and flatMap()? The map() transformation takes in a function and applies it to each element in the RDD with the result of the function being the new value of each element in the resulting RDD. Sometimes we want to produce multiple output elements for each input element. The operation to do this is called flatMap(). As with map(), the function we provide to flatMap() is called individually for each element in our input RDD. Instead of returning a single element, we return an iterator with our return values. 86.What is reduce() action? It takes a function that operates on two elements of the type in your RDD and returns a new element of the same type. A simple example of such a function is +, which we can use to sum our RDD. With reduce(), we can easily sum the elements of our RDD, count the number of elements, and perform other types of aggregations. 87.What is Piping? Spark provides a pipe() method on RDDs. Spark’s pipe() lets us write parts of jobs using any language we want as long as it can read and write to Unix standard streams. With pipe(), you can write a transformation of an RDD that reads each RDD element from standard input as a String, manipulates that String however you like, and then writes the result(s) as Strings to standard output. 88.What are benefits of Spark over MapReduce? Due to the availability of in-memory processing, Spark implements the processing around 10-100x faster than Hadoop MapReduce. MapReduce makes use of persistence storage for any of the data processing tasks. Unlike Hadoop, Spark provides in-built libraries to perform multiple tasks form the same core like batch processing, Steaming, Machine learning, Interactive SQL queries. However, Hadoop only supports batch processing. Hadoop is highly disk-dependent whereas Spark promotes caching and in-memory data storage Spark is capable of performing computations multiple times on the same dataset. This is called iterative computation while there is no iterative computing implemented by Hadoop. 89.Is there any benefit of learning MapReduce, then? Yes, MapReduce is a paradigm used by many big data tools including Spark as well. It is extremely relevant to use MapReduce when the data grows bigger and bigger. Most tools like Pig and Hive convert their queries into MapReduce phases to optimize them better. 90.What is Spark SQL? Spark SQL is a module in Apache Spark that integrates relational processing(e.g., declarative queries and optimized storage) with Spark’s procedural programming API. Spark SQL makes two main additions.First, it offers much tighter integration between relational and procedural processing, through a declarative DataFrame API.Second, it includes a highly extensible optimizer, Catalyst. Big data applications require a mix of processing techniques, data sources and storage formats. The earliest systems designed for these workloads, such as MapReduce, gave users a powerful, but low-level, procedural programming interface. Programming such systems was onerous and required manual optimization by the user to achieve high performance. As a result, multiple new systems sought to provide a more productive user experience by offering relational interfaces to big data. Systems like Pig, Hive and Shark all take advantage of declarative queries to provide richer automatic optimizations. 91.What is a schema RDD/DataFrame? A SchemaRDD is an RDD composed of Row objects with additional schema information of the types in each column. Row objects are just wrappers around arrays of basic types (e.g., integers and strings). 92.What are Row objects? Row objects represent records inside SchemaRDDs, and are simply fixed-length arrays of fields.Row objects have a number of getter functions to obtain the value of each field given its index. The standard getter, get (or apply in Scala), takes a column number and returns an Object type (or Any in Scala) that we are responsible for casting to the correct type. For Boolean, Byte, Double, Float, Int, Long, Short, and String, there is a getType() method, which returns that type. For example, get String(0) would return field 0 as a string. 93.What are DStreams? Much like Spark is built on the concept of RDDs, Spark Streaming provides an abstraction called DStreams, or discretized streams. A DStream is a sequence of data arriving over time. Internally, each DStream is represented as a sequence of RDDs arriving at each time step. DStreams can be created from various input sources, such as Flume, Kafka, or HDFS. Once built, they offer two types of operations: transformations, which yield a new DStream, and output operations, which write data to an external system. 94.Explain Spark Streaming Architecture? Spark Streaming uses a “micro-batch” architecture, where Spark Streaming receives data from various input sources and groups it into small batches. New batches are created at regular time intervals. At the beginning of each time interval a new batch is created, and any data that arrives during that interval gets added to that batch. At the end of the time interval the batch is done growing. The size of the time intervals is determined by a parameter called the batch interval. Each input batch forms an RDD, and is processed using Spark jobs to create other RDDs. The processed results can then be pushed out to external systems in batches. 95.What are the types of Transformations on DStreams? In stateless transformations the processing of each batch does not depend on the data of its previous batches. They include the common RDD transformations like map(), filter(), and reduceByKey(). • Stateful transformations, in contrast, use data or intermediate results from previous batches to compute the results of the current batch. They include transformations based on sliding windows and on tracking state across time. 96.What is Receiver in Spark Streaming? Every input DStream is associated with a Receiver object which receives the data from a source and stores it in Spark’s memory for processing. 97.How Spark achieves fault tolerance? Spark stores data in-memory whereas Hadoop stores data on disk. Hadoop uses replication to achieve fault tolerance whereas Spark uses different data storage model, RDD. RDDs achieve fault tolerance through a notion of lineage: if a partition of an RDD is lost, the RDD has enough information to rebuild just that partition.This removes the need for replication to achieve fault tolerance. 98.What are Spark’s main features? Speed : Spark enables applications in Hadoop clusters to run up to 100x faster in memory, and 10x faster even when running on disk. Spark makes it possible by reducing number of read/write to disc. It stores this intermediate processing data in-memory. It uses the concept of an Resilient Distributed Dataset (RDD), which allows it to transparently store data on memory and persist it to disc only it’s needed. This helps to reduce most of the disc read and write – the main time consuming factors – of data processing. Combines SQL, streaming, and complex analytics: In addition to simple “map” and “reduce” operations, Spark supports SQL queries, streaming data, and complex analytics such as machine learning and graph algorithms out-of-the-box. Not only that, users can combine all these capabilities seamlessly in a single workflow. Ease of Use:Spark lets you quickly write applications in Java, Scala, or Python. This helps developers to create and run their applications on their familiar programming languages and easy to build parallel apps. Runs Everywhere: Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, S3. 99.Explain about the popular use cases of Apache Spark? Apache Spark is mainly used for Iterative machine learning. Interactive data analytics and processing. Stream processing Sensor data processing 100.Is Apache Spark a good fit for Reinforcement learning? No. Apache Spark works well only for simple machine learning algorithms like clustering, regression, classification. 101.How can you remove the elements with a key present in any other RDD? Use the subtractByKey () function 102.How Spark handles monitoring and logging in Standalone mode? Spark has a web based user interface for monitoring the cluster in standalone mode that shows the cluster and job statistics. The log output for each job is written to the work directory of the slave nodes. 103.Does Apache Spark provide checkpointing? Lineage graphs are always useful to recover RDDs from a failure but this is generally time consuming if the RDDs have long lineage chains. Spark has an API for check pointing i.e. a REPLICATE flag to persist. However, the decision on which data to checkpoint - is decided by the user. Checkpoints are useful when the lineage graphs are long and have wide dependencies. 104.How can you launch Spark jobs inside Hadoop MapReduce? Using SIMR (Spark in MapReduce) users can run any spark job inside MapReduce without requiring any admin rights. 105.How Spark uses Akka? Spark uses Akka basically for scheduling. All the workers request for a task to master after registering. The master just assigns the task. Here Spark uses Akka for messaging between the workers and masters. 106.How can you achieve high availability in Apache Spark? Implementing single node recovery with local file system Using StandBy Masters with Apache ZooKeeper. 107.Hadoop uses replication to achieve fault tolerance. How is this achieved in Apache Spark? Data storage model in Apache Spark is based on RDDs. RDDs help achieve fault tolerance through lineage. RDD always has the information on how to build from other datasets. If any partition of a RDD is lost due to failure, lineage helps build only that particular lost partition. 108.Explain about the core components of a distributed Spark application. Driver- The process that runs the main () method of the program to create RDDs and perform transformations and actions on them. Executor –The worker processes that run the individual tasks of a Spark job. Cluster Manager-A pluggable component in Spark, to launch Executors and Drivers. The cluster manager allows Spark to run on top of other external managers like Apache Mesos or YARN. 109.What do you understand by Lazy Evaluation? Spark is intellectual in the manner in which it operates on data. When you tell Spark to operate on a given dataset, it heeds the instructions and makes a note of it, so that it does not forget - but it does nothing, unless asked for the final result. When a transformation like map () is called on a RDD-the operation is not performed immediately. Transformations in Spark are not evaluated till you perform an action. This helps optimize the overall data processing workflow. 110.Define a worker node? A node that can run the Spark application code in a cluster can be called as a worker node. A worker node can have more than one worker which is configured by setting the SPARK_ WORKER_INSTANCES property in the spark-env.sh file. Only one worker is started if the SPARK_ WORKER_INSTANCES property is not defined. 111.What do you understand by SchemaRDD? An RDD that consists of row objects (wrappers around basic string or integer arrays) with schema information about the type of data in each column. 112.Explain groupByKey vs reduceByKey in Apache Spark? On applying groupByKey() on a dataset of (K, V) pairs, the data shuffle according to the key value K in another RDD. In this transformation, lots of unnecessary data transfer over the network. Spark provides the provision to save data to disk when there is more data shuffling onto a single executor machine than can fit in memory. Example: val data = spark.sparkContext.parallelize(Array(('k',5),('s',3),('s',4),('p',7),('p',5),('t',8),('k',6)),3) val group = data.groupByKey().collect() group.foreach(println) On applying reduceByKey on a dataset (K, V), before shuffeling of data the pairs on the same machine with the same key are combined. Example: val words = Array("one","two","two","four","five","six","six","eight","nine","ten") val data = spark.sparkContext.parallelize(words).map(w => (w,1)).reduceByKey(_+_) data.foreach(println) 113.Explain foreach() operation in apache spark ? foreach() operation is an action. > It do not return any value. > It executes input function on each element of an RDD. It executes the function on each item in RDD. It is good for writing database or publishing to web services. It executes parameter less function for each data items. Example: val mydata = Array(1,2,3,4,5,6,7,8,9,10) val rdd1 = sc.parallelize(mydata) rdd1.foreach{x=>println(x)} OR rdd1.foreach{println} Output: 1 2 3 4 5 6 7 8 9 10 114.Explain distnct(),union(),intersection() and substract() transformation in Spark? distnct() transformation If one want only unique elements in a RDD in that case one can use d1.distnct() where d1 is RDD Example val d1 = sc.parallelize(List("c","c","p","m","t")) val result = d1.distnct() result.foreach{println} OutPut: p t m c union() transformation Its simplest set operation. rdd1.union(rdd2) which outputs a RDD which contains the data from both sources. If the duplicates are present in the input RDD, output of union() transformation will contain duplicate also which can be fixed using distinct(). Example val u1 = sc.parallelize(List("c","c","p","m","t")) val u2 = sc.parallelize(List("c","m","k")) val result = u1.union(u2) result.foreach{println} Output: c c p m t c m k intersection() transformation intersection(anotherrdd) returns the elements which are present in both the RDDs. intersection(anotherrdd) remove all the duplicate including duplicated in single RDD val is1 = sc.parallelize(List("c","c","p","m","t")) val is2 = sc.parallelize(List("c","m","k")) val result = is1.union(is2) result.foreach{println} Output : m c subtract() transformation Subtract(anotherrdd). It returns an RDD that has only value present in the first RDD and not in second RDD. Example val s1 = sc.parallelize(List("c","c","p","m","t")) val s2 = sc.parallelize(List("c","m","k")) val result = s1.subtract(s2) result.foreach{println} Output: t p Adding one more point about distinct() transformation: distinct() transformation is expensive operation as it requires shuffling all the data over the network to ensure that we receive only one copy of each element 115.Explain sortByKey() operation.? sortByKey() is a transformation. > It returns an RDD sorted by Key. > Sorting can be done in (1) Ascending OR (2) Descending OR (3) custom sorting They will work with any key type K that has an implicit Ordering[K] in scope. Ordering objects already exist for all of the standard primitive types. Users can also define their own orderings for custom types, or to override the default ordering. The implicit ordering that is in the closest scope will be used. When called on Dataset of (K, V) where k is Ordered returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the ascending argument. Adding one more point on sortByKey() operation is , the result of sortByKey() is based on range-partitioned RDD DAG will start evaluating when we call sortByKey even though we don’t action API. In general, DAG will evaluated only when we call an action. But in case of sortByKey, it start evaluating the DAG in order to compute total of partitions. Don’t think that we will get the result when we call sortByKey api. I have seen this DAG evaluation in WEB API. sortByKey api return type is RDD which is paired rdd. Out of all transformations available in spark, I think this is the only api that triggers DAG evaluation. For remaining transformation, DAG won’t be evaluated until we call an action. Example : <br /> val rdd1 = sc.parallelize(Seq(("India",91),("USA",1),("Brazil",55),("Greece",30),("China",86),("Sweden",46),("Turkey",90),("Nepal",977)))<br /> val rdd2 = rdd1.sortByKey()<br /> rdd2.collect();<br /> Output: Array[(String,Int)] = (Array(Brazil,55),(China,86),(Greece,30),(India,91),(Nepal,977),(Sweden,46),(Turkey,90),(USA,1) <br /> val rdd1 = sc.parallelize(Seq(("India",91),("USA",1),("Brazil",55),("Greece",30),("China",86),("Sweden",46),("Turkey",90),("Nepal",977)))<br /> val rdd2 = rdd1.sortByKey(false)<br /> rdd2.collect();<br /> 116.Explain mapPartitions() and mapPartitionsWithIndex()? mapPartitions() and mapPartitionsWithIndex() are both transformation. mapPartitions() : > mapPartitions() can be used as an alternative to map() and foreach() . > mapPartitions() can be called for each partitions while map() and foreach() is called for each elements in an RDD > Hence one can do the initialization on per-partition basis rather than each element basis mapPartitions() : > mapPartitionsWithIndex is similar to mapPartitions() but it provides second parameter index which keeps the track of partition. MapPartitions: It runs one at a time on each partition or block of the Rdd, so function must be of type iterator<T>. It improves performance by reducing creation of object in map function. MappartionwithIndex: It is similar to MapPartition but with one difference that it takes two parameters, the first parameter is the index and second is an iterator through all items within this partition (Int, Iterator<t>). 117.Explain cogroup() operation in Spark? It’s a transformation. It’s in package org.apache.spark.rdd.PairRDDFunctions def cogroup[W1, W2, W3](other1: RDD[(K, W1)], other2: RDD[(K, W2)], other3: RDD[(K, W3)]): RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] For each key k in this or other1 or other2 or other3, return a resulting RDD that contains a tuple with the list of values for that key in this, other1, other2 and other3. Example: val myrdd1 = sc.parallelize(List((1,"spark"),(2,"HDFS"),(3,"Hive"),(4,"Flink"),(6,"HBase"))) val myrdd2 = sc.parallelize(List((4,"RealTime"),(5,"Kafka"),(6,"NOSQL"),(1,"stream"),(1,"MLlib"))) val result = myrdd1.cogroup(myrdd2) result.collect Output : Array[(Int, (Iterable[String], Iterable[String]))] = Array((4,(CompactBuffer(Flink),CompactBuffer(RealTime))), (1,(CompactBuffer(spark),CompactBuffer(stream, MLlib))), (6,(CompactBuffer(HBase),CompactBuffer(NOSQL))), (3,(CompactBuffer(Hive),CompactBuffer())), (5,(CompactBuffer(),CompactBuffer(Kafka))), (2,(CompactBuffer(HDFS),CompactBuffer()))) 118.Explain Spark coalesce() operation ? It is a transformation. It’s in a package org.apache.spark.rdd.ShuffledRDD def coalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[(K, C)] = null): RDD[(K, C)] Return a new RDD that is reduced into numPartitions partitions. This results in a narrow dependency, e.g. if you go from 1000 partitions to 100 partitions, there will not be a shuffle, instead, each of the 100 new partitions will claim 10 of the current partitions. However, if you’re doing a drastic coalesce, e.g. to numPartitions = 1, this may result in your computation taking place on fewer nodes than you like (e.g. one node in the case of numPartitions = 1). To avoid this, you can pass shuffle = true. This will add a shuffle step but means the current upstream partitions will be executed in parallel (per whatever the current partitioning is). Note: With shuffle = true, you can actually coalesce to a larger number of partitions. This is useful if you have a small number of partitions, say 100, potentially with a few partitions being abnormally large. Calling coalesce(1000, shuffle = true) will result in 1000 partitions with the data distributed using a hash partitioner. It changes a number of the partition where data is stored. It combines original partitions to a new number of partitions, so it reduces the number of partitions. It is an optimized version of repartition that allows data movement, but only if you are decreasing the number of RDD partitions. It runs operations more efficiently after filtering large datasets. Example : val myrdd1 = sc.parallelize(1 to 1000, 15) myrdd1.partitions.length val myrdd2 = myrdd1.coalesce(5,false) myrdd2.partitions.length Int = 5 Output : Int = 15 Int = 5 119.What is PageRank in Spark? 120.RDD vs DataFrame vs DataSet ? Short Combined Intro : Before discussing each one separately, want to start with a short combined intro.Evolution of these abstractions happened in this way : RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6) RDD being the oldest available from 1.0 version to Dataset being the newest available from 1.6 version.Given same data, each of the 3 abstraction will compute and give same results to user. But they differ in performance and the ways they compute. RDD lets us decide HOW we want to do which limits the optimisation Spark can do on processing underneath where as dataframe/dataset lets us decide WHAT we want to do and leave everything on Spark to decide how to do computation. We will understand this in 2 minutes what is meant by HOW & WHAT . Dataframe came as a major performance improvement over RDD but not without some downsides.This led to development of Dataset which is an effort to unify best of RDD and data frame.In future, Dataset will eventually replace RDD and Dataframe to become the only API spark users should be caring about while writing code.Lets understand them in detail one by one. RDD: Its building block of spark. No matter which abstraction Dataframe or Dataset we use, internally final computation is done on RDDs. RDD is lazily evaluated immutable parallel collection of objects exposed with lambda functions. The best part about RDD is that it is simple. It provides familiar OOPs style APIs with compile time safety. We can load any data from a source,convert them into RDD and store in memory to compute results. RDD can be easily cached if same set of data needs to recomputed. But the disadvantage is performance limitations. Being in-memory jvm objects, RDDs involve overhead of Garbage Collection and Java(or little better Kryo) Serialization which are expensive when data grows. RDD example:
Dataframe: DataFrame is an abstraction which gives a schema view of data. Which means it gives us a view of data as columns with column name and types info, We can think data in data frame like a table in database. Like RDD, execution in Dataframe too is lazy triggered . offers huge performance improvement over RDDs because of 2 powerful features it has: 1. Custom Memory management (aka Project Tungsten) Data is stored in off-heap memory in binary format. This saves a lot of memory space. Also there is no Garbage Collection overhead involved. By knowing the schema of data in advance and storing efficiently in binary format, expensive java Serialization is also avoided. 2. Optimized Execution Plans (aka Catalyst Optimizer) Query plans are created for execution using Spark catalyst optimiser. After an optimised execution plan is prepared going through some steps, the final execution happens internally on RDDs only but thats completely hidden from the users. Just to give an example of optimisation with respect to the above picture, lets consider a query as below : In the above query, filter is used before join which is a costly shuffle operation. The logical plan sees that and in optimised logical plan, this filter is pushed to execute before join. In the optimised execution plan, it can leverage datasource capabilities also and push that filter further down to datasource so that it can apply that filter on the disk level rather than bringing all data in memory and doing filter in memory (which is not possible while directly using RDDs). So filter method now effectively works like a WHERE clause in a database query. Also with optimised data sources like parquet , if Spark sees that you need only few columns to compute the results , it will read and fetch only those columns from parquet saving both disk IO and memory. Downside of Dataframe : Lack of Type Safety. As a developer, i will not like using dataframe as it doesn't seem developer friendly. Referring attribute by String names means no compile time safety. Things can fail at runtime. Also APIs doesn't look programmatic and more of sql kind. Dataframe example: 2 ways to define: 1. Expression BuilderStyle 2. SQL Style As discussed, If we try using some columns not present in schema, we will get problem only at runtime . For example, if we try accessing salary when only name and age are present in the schema will exception like below:
Dataset: It is an extension to Dataframe API, the latest abstraction which tries to provide best of both RDD and Dataframe. comes with OOPs style and developer friendly compile time safety like RDD as well as performance boosting features of Dataframe : Catalyst optimiser and custom memory management. How dataset scores over Dataframe is an additional feature it has: Encoders Encoders act as interface between JVM objects and off-heap custom memory binary format data. Encoders generate byte code to interact with off-heap data and provide on-demand access to individual attributes without having to de-serialize an entire object. case class is used to define the structure of data schema in Dataset. Using case class, its very easy to work with dataset. Names of different attributes in case class is directly mapped to field names in Dataset . It gives feeling like working with RDD but actually underneath it works same as Dataframe. Dataframe is infact treated as dataset of generic row objects.DataFrame=Dataset[Row] . So we can always convert a data frame at any point of time into a dataset by calling ‘as’ method on Dataframe. e.g. df.as[MyClass] Dataset Example : Important point to remember is that both Dataset and DataFrame internally does final execution on RDD objects only but the difference is users do not write code to create the RDD collections and have no control as such over RDDs. RDDs are created in the execution plan as last stage after deciding and going through all the optimizations (see Execution Plan Diagram). Thats why at the beginning of this post , it says……..RDD let us decide HOW we want to do where as Dataframe/Dataset lets us decide WHAT we want to do. And all these optimisations could have been possible because data is structured and Spark knows about the schema of data in advance. So it can apply all the powerful features like tungsten custom memory off-heap binary storage,catalyst optimiser and encoders to get the performance which was not possible if users would have been directly working on RDD. Conclusion: In short, Spark is moving from unstructured computation(RDDs) towards structured computation because of many performance optimisations it allows . Data frame was a step in direction of structured computation but lacked developer friendliness of compile time safety,lambda functions. Finally Dataset is the unification of Dataframe and RDD to bring the best abstraction out of two.Going forward developers should only be concerned about DataSet while Dataframe and RDD will be discouraged to use.
But its always better to be aware of the legacy for better understanding of internals. 121. RDD = RDD1(5 partitions) union RDD2(10 partitions). How many partitions in result RDD? 15 partitions 122.What is repartition? Difference between coalesce() and repartition? Spark splits data into partitions and computation is done in parallel for each partition. It is very important to understand how data is partitioned and when you need to manually modify the partitioning to run spark application efficiently. In Spark RDD API there are 2 methods available to increase or decrease the number of partitions. repartition() method and coalesce() method val data = 1 to 15 val numOfPartitions = 5 val rdd = spark.sparkContext.parallelize(data , numOfPartitions) rdd.getNumPartitions 5 rdd.saveAsTextFile("C:/npntraining/output_rdd") In the above program we are creating an rdd with 5 partitions and then we are saving an rdd by invoking saveAsTextFile(str:String) method. If you open the output_rdd for each partition one output file will be created part-00000 : 1 2 3 part-00001 : 4 5 6 part-00002 : 7 8 9 part-00003 : 10 11 12 part-00004 : 13 14 15 coalesce() method coalesce() uses existing partitions to minimize the amount of data that’s shuffled coalesce results in partitions with different amounts of data (sometimes partitions that have much different sizes) val coalesceRDD = rdd.coalesceRDD(3) coalesceRDD.saveAsTextFile("C:/npntraining/coalesce-output"); part-00000 : 1 2 3 part-00001 : 4 5 6 7 8 9 part-00002 : 10 11 12 13 14 15 If you analyze the output the data from partition part-00002 is merged with part-00001 and data from partition-0004 is merged with part-00002 hence minimize the amount of data that’s shuffled but results in partitions with different amounts of data [Important] One difference I know is that with repartition() the number of partitions can be increased/decreased, but with coalesce() the number of partitions can only be decreased. repartition() method The repartition method can be used to either increase or decrease the number of partitions in a RDD. val repartitionRDD = rdd.repartition(3) repartition.saveAsTextFile("C:/npntraining/repartition-output"); part-00000 : 3 6 8 10 13 part-00001 : 1 4 9 11 14 part-00002 : 2 5 7 12 15
If you analyze the entire data is shuffled i.e but data is equally partitioned across the partitions [Important]
Summary Of Difference
coalesce()
repartition()
Used to reduce the number of partitions
Used to reduce or decrease the number of partitions.
Tries to minimize data movement by avoiding network shuffle.
A network shuffle will be triggered which can increase data movement.
Creates unequal sized partitions
Creates equal sized partitions
123. cache() and persist only Memory difference? 124. Difference between reducebykey vs aggregatebykey ?
While both reducebykey and groupbykey will produce the same answer, the reduceByKey example works much better on a large dataset. That’s because Spark knows it can combine output with a common key on each partition before shuffling the data.
On the other hand, when calling groupByKey – all the key-value pairs are shuffled around. This is a lot of unnessary data to being transferred over the network.
Syntax:
sparkContext.textFile("hdfs://")
.flatMap(line => line.split(" "))
.map(word => (word,1))
.reduceByKey((x,y)=> (x+y))
Data is combined at each partition , only one output for one key at each partition to send over network. reduceByKey required combining all your values into another value with the exact same type.
GroupByKey – groupByKey([numTasks])
It doesn’t merge the values for the key but directly the shuffle process happens and here lot of data gets sent to each partition, almost same as the initial data.
And the merging of values for each key is done after the shuffle. Here lot of data stored on final worker node so resulting in out of memory issue.
Syntax:
sparkContext.textFile("hdfs://")
.flatMap(line => line.split(" "))
.map(word => (word,1))
.groupByKey()
.map((x,y) => (x,sum(y)))
groupByKey can cause out of disk problems as data is sent over the network and collected on the reduce workers
AggregateByKey – aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) It is similar to reduceByKey but you can provide initial values when performing aggregation.
same as reduceByKey, which takes an initial value.
3 parameters as input i. initial value ii. Combiner logic iii. sequence op logic
val countByKey = kv.aggregateByKey(initialCount)(addToCounts, sumPartitionCounts)
ouput: Aggregate By Key sum Results bar -> 3 foo -> 5
groupByKey() is just to group your dataset based on a key.
reduceByKey() is something like grouping + aggregation.
reduceByKey can be used when we run on large data set.
reduceByKey when the input and output value types are of same type over aggregateByKey
aggregateByKey() is logically same as reduceByKey() but it lets you return result in different type. In another words, it lets you have a input as type x and aggregate result as type y. For example (1,2),(1,4) as input and (1,”six”) as output.
125.where does the driver program run ? 126.How does Spark decide how many partitions should be there in an RDD or Dataframe? 127. DAG vs Lineage Graph?
Lineage graph
As we know, that whenever a series of transformations are performed on an RDD, they are not evaluated immediately, but lazily(Lazy Evaluation). When a new RDD has been created from an existing RDD, that new RDD contains a pointer to the parent RDD. Similarly, all the dependencies between the RDDs will be logged in a graph, rather than the actual data. This graph is called the lineage graph.
Now coming to DAG,
Directed Acyclic Graph(DAG)
DAG in Apache Spark is a combination of Vertices as well as Edges. In DAG vertices represent the RDDs and the edges represent the Operation to be applied on RDD. Every edge in DAG is directed from earlier to later in a sequence.When we call anAction, the created DAG is submitted to DAG Scheduler which further splits the graph into the stages of the task.
128.Explain Lazy evaluation?
Lazy evaluation means the execution will not start until an action is triggered. Transformations are lazy in nature i.e. when we call some operation on RDD, it does not execute immediately. Spark adds them to a DAG of computation and only when driver requests some data, this DAG actually gets executed
Advantages of lazy evaluation.
1) It is an optimization technique i.e. it provides optimization by reducing the number of queries.
2) It saves the round trips between driver and cluster, thus speeds up the process.
129.Narrow vs Wide Transformations ?
Narrow transformation – In Narrow transformation, all the elements that are required to compute the records in single partition live in the single partition of parent RDD. A limited subset of partition is used to calculate the result. Narrow transformations are the result of map(), filter()
Wide transformation – In wide transformation, all the elements that are required to compute the records in the single partition may live in many partitions of parent RDD. The partition may live in many partitions of parent RDD. Wide transformations are the result of groupbyKey() and reducebyKey().


I am happy for sharing on this blog its awesome blog I really impressed. thanks for sharing. Great efforts.
ReplyDeleteLooking for Big Data Hadoop Training Institute in Bangalore, India. Prwatech is the best one to offers computer training courses including IT software course in Bangalore, India.
Also it provides placement assistance service in Bangalore for IT. Spark Training institute in Bangalore.
Thanks for Feedback. I will come up with latest questions including the programming.
ReplyDeleteThanks for Feedback. I will come up with latest questions.
ReplyDeleteThis comment has been removed by the author.
ReplyDelete